采集规则示例
采集文章流程:列表页 → 获取内容页网址 → 内容页字段分析
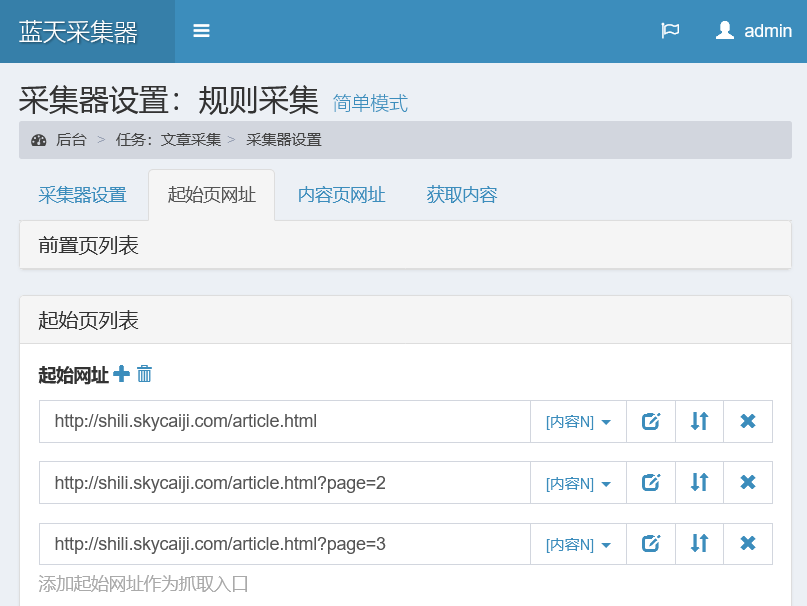
起始页网址
以http://shili.skycaiji.com/article.html为例,所有文章都在该列表中,即起始页为该网址
可添加多个起始页(例如列表分页)
内容页网址
点击“保存”后我们在“内容页网址”的底部点击“测试按钮»测试抓取内容页网址”

默认会抓取所有网址(包括样式和js文件)
有些网址不包含域名(因为程序是直接抓取html源码的),可以在“采集器设置”里选中“自动补全网址”
我们只需要采集文章页面,通过分析文章网址的格式大致为“article/news/show/id/数字.html”
直接在“结果网址过滤»必须包含”中输入:article/news/show/id/ 保存后测试看看


如需精准还可以输入正则:article/news/show/id/\d+\.html(\d+是匹配数字)
想过滤某些网址可以在“不能包含”中输入,例如过滤掉25、27、29的文章,输入:25|27|29 即可
如果列表页布局比较复杂有很多个文章列表区域,而我们仅需要获取某个区域的文章,可以使用“从选定区域中提取网址”,新手推荐“xpath”获取形式,可在“底部测试按钮»测试分析网页”中输入列表页网址,点击页面元素即可获取相应的xpath值
如果内容页链接不能直接获取(通过js生成)或者需要拼接成新网址,可以在“匹配内容网址”中设置
获取内容
分析出内容页网址后,我们需要抓取文章的标题、正文等信息则要添加字段来匹配出数据
新手推荐使用“xpath”匹配,在“底部测试按钮»测试分析网页”中输入一个文章链接
分析页面中点击获取到标题xpath://*[@id="title"]/h1[1],正文xpath://*[@id="content"]
分别添加字段:标题、正文,获取方式选择“xpath匹配”,将获取到的xpath值填入即可

保存后点击测试抓取数据,效果:

正文中包含很多html标签,如需过滤可使用“数据处理»html标签过滤”功能
如需采集分页内容,请参考文章分页教程
本示例已上传至云平台http://www.skycaiji.com/rule/100114